




Large Language Models (LLMs) are transforming how we interact with technology. This blog provides a comprehensive overview of LLMs, explaining their mechanics, training processes, and applications in everyday life.
Table of Contents
- Who This Was Made For
- Introduction to Large Language Models
- The Magic of Prediction
- Understanding the Output
- The Training Process
- Parameters and Their Importance
- Pre-training and Its Scale
- Reinforcement Learning with Human Feedback
- The Role of GPUs in Training
- Introduction of Transformers
- How Transformers Work
- Attention Mechanism Explained
- Emergent Behavior in LLMs
- The Practical Applications of LLMs
- Where to Learn More
- FAQ
Who This Was Made For
This blog post is designed for anyone curious about the intricacies of Large Language Models (LLMs). Whether you’re a tech enthusiast, a student, or simply someone interested in how AI interacts with language, this content aims to demystify complex concepts. It serves as a bridge for those who may not have a technical background but are eager to understand the significant impact LLMs have on our daily lives.
Introduction to Large Language Models
Large Language Models (LLMs) are advanced AI systems that process and generate human-like text. They operate on the principle of predicting the next word in a sequence based on the context provided by preceding words. This predictive capability enables them to engage in conversations, write essays, and even create poetry.
At their core, LLMs utilize vast amounts of textual data to learn language patterns. They are designed to understand context, syntax, and semantics, making them remarkably versatile. The sheer scale of data and the complexity of their architecture set them apart from traditional models.

The Magic of Prediction
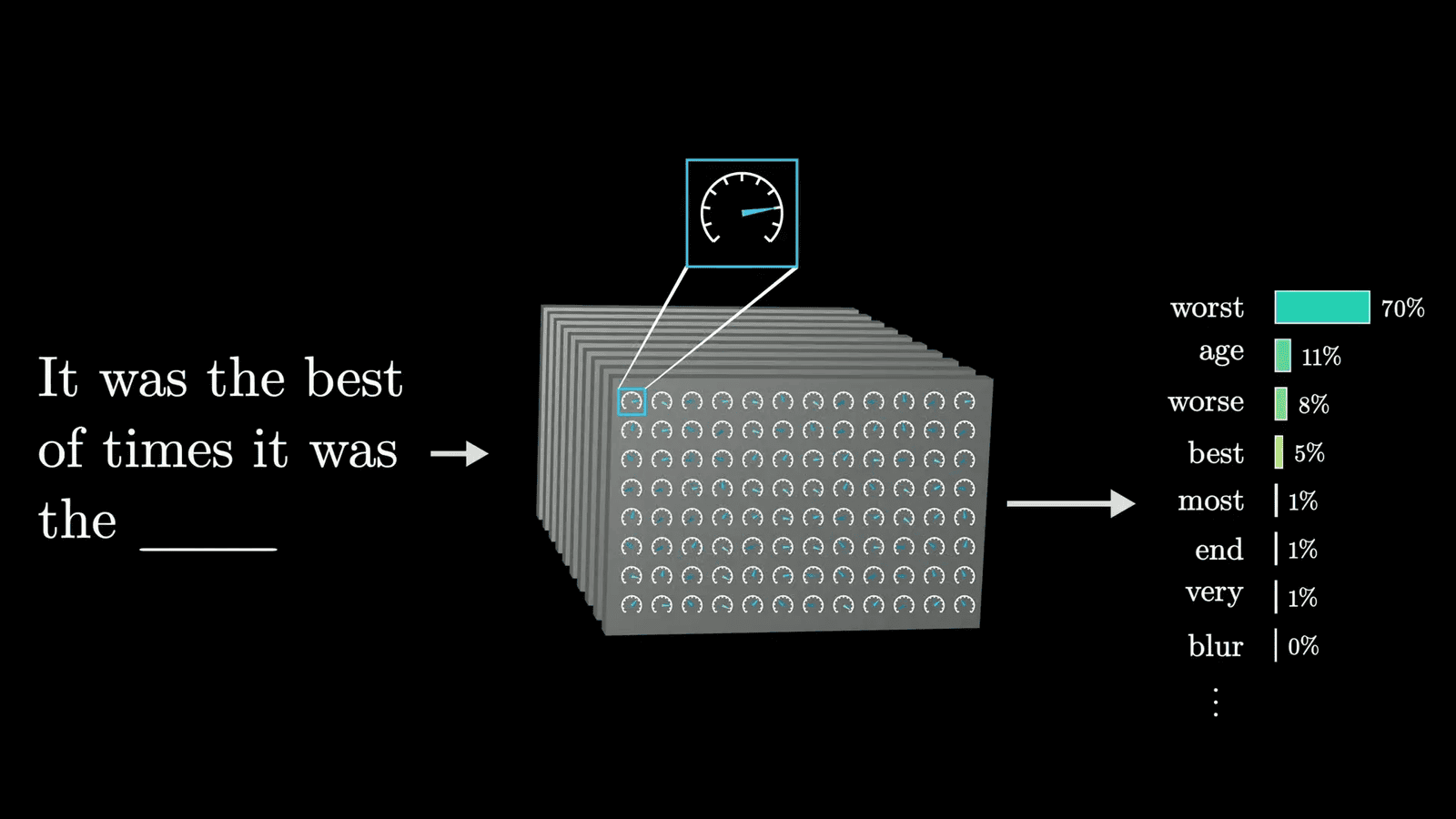
The magic of LLMs lies in their ability to predict the next word in a sentence. When given a prompt, the model evaluates countless possibilities and assigns probabilities to each potential next word. This probabilistic approach allows for more natural and varied outputs, as the model can select less likely words at random, creating a more human-like conversation.
For instance, when you type a question into a chatbot, the LLM analyzes the input and generates a response by predicting the most suitable next words based on its training. The result is a coherent answer that often feels intuitive and contextually appropriate.

Understanding the Output
The output generated by LLMs can be strikingly fluent and coherent. However, understanding how these predictions are formed involves recognizing that the model does not truly “know” language; it merely predicts based on patterns learned during training. Each output reflects the underlying statistical relationships between words rather than a genuine understanding of meaning.
This distinction is crucial for users to grasp. While LLMs can produce impressive results, their responses are ultimately a reflection of the data they have been trained on, which may include biases or inaccuracies. Being aware of this helps set realistic expectations when interacting with these models.

The Training Process
The training process of an LLM involves two main phases: pre-training and fine-tuning. During pre-training, the model ingests vast amounts of text data, learning to predict the next word in a sentence. This phase requires enormous computational resources and is where the model develops its foundational language skills.
Following pre-training, fine-tuning occurs. This stage is critical for adapting the model to specific tasks or improving its performance based on human feedback. By identifying and correcting unhelpful predictions, trainers refine the model further, enhancing its ability to generate relevant and accurate responses.

Parameters and Their Importance
Parameters, often referred to as weights, are the backbone of LLMs. These continuous values determine how the model behaves and make predictions. The “large” in Large Language Models stems from the staggering number of parameters they contain, often numbering in the hundreds of billions.
Each parameter adjusts the model’s output during training. Initially set at random, these parameters are fine-tuned through a process called backpropagation. This iterative refinement allows the model to improve its predictions over time, ultimately leading to more accurate and contextually appropriate outputs.

Pre-training and Its Scale
The pre-training phase is a monumental undertaking in the lifecycle of an LLM. During this stage, the model consumes vast datasets, learning to predict the next word in a sequence. The amount of text processed is staggering, often exceeding trillions of words, which requires immense computational power.
For context, if a human were to read the quantity of text used to train models like GPT-3, it would take over 2600 years of non-stop reading. This scale of data is essential for the model to understand language nuances and context, enabling it to generate coherent and contextually appropriate responses.

Reinforcement Learning with Human Feedback
After pre-training, LLMs undergo a crucial phase known as reinforcement learning with human feedback (RLHF). This process fine-tunes the model based on real user interactions. Human trainers evaluate the model’s outputs, flagging any unhelpful or problematic responses.
By incorporating this feedback, the model’s parameters are adjusted to enhance its ability to generate preferred responses. This iterative process ensures that the LLM evolves and becomes more aligned with human expectations and preferences.

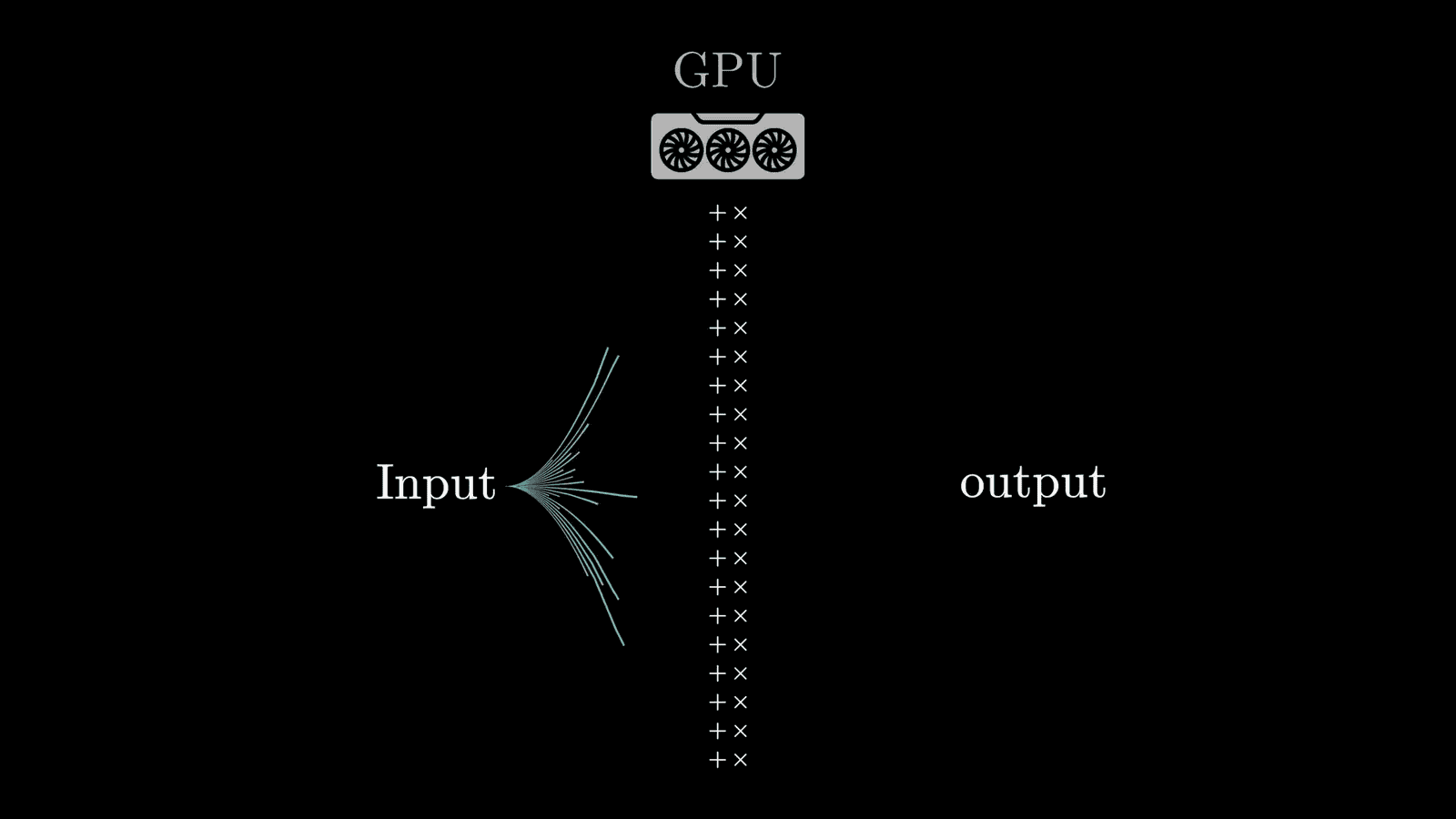
The Role of GPUs in Training
The training of LLMs is heavily reliant on Graphics Processing Units (GPUs). These specialized chips are designed for parallel processing, allowing multiple operations to occur simultaneously. This capability is essential when dealing with the enormous computational requirements of training large models.
Without GPUs, the training process would be drastically slower and less efficient. The ability to perform billions of calculations per second is what enables researchers to refine models in a reasonable timeframe, despite the massive scale of data involved.
Introduction of Transformers
The introduction of transformers marked a significant shift in the architecture of language models. Prior to their development, models processed text sequentially, which limited their efficiency. Transformers, however, read entire sequences of text simultaneously, allowing for greater context and parallelization.
This innovative architecture enables models to capture relationships between words more effectively, leading to improved predictions and more fluent outputs. The transformer model has become the backbone of many modern LLMs due to its efficiency and effectiveness.
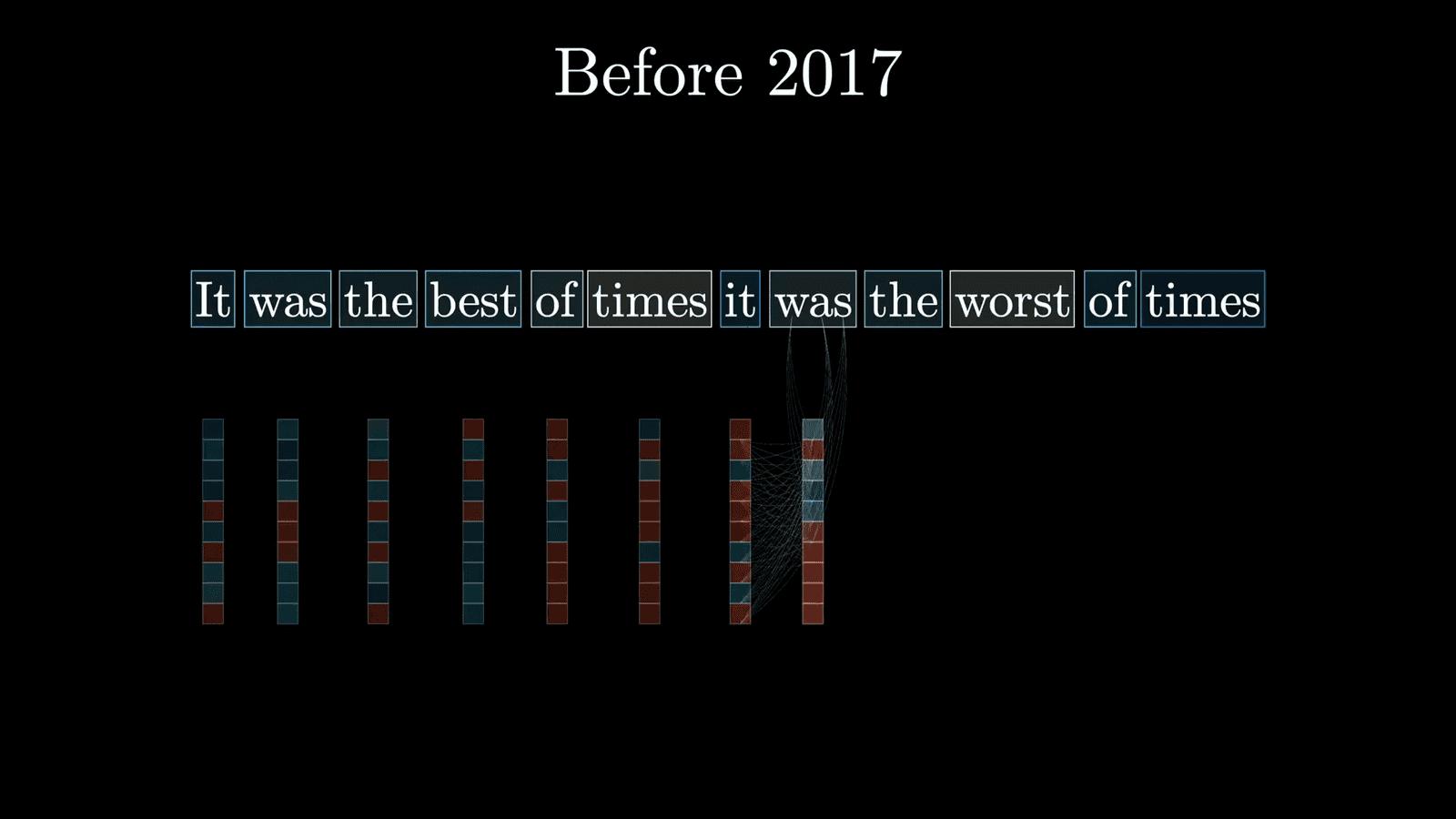
How Transformers Work
Transformers operate by converting words into numerical representations, allowing the model to process and understand language in a mathematical framework. Each word is transformed into a list of numbers that encodes its meaning. This encoding is essential for the training process, which relies on continuous values.
Once the words are encoded, the model applies two key operations: attention and feed-forward neural networks. These operations work together to refine the understanding of each word based on its context within the entire input sequence.
Attention Mechanism Explained
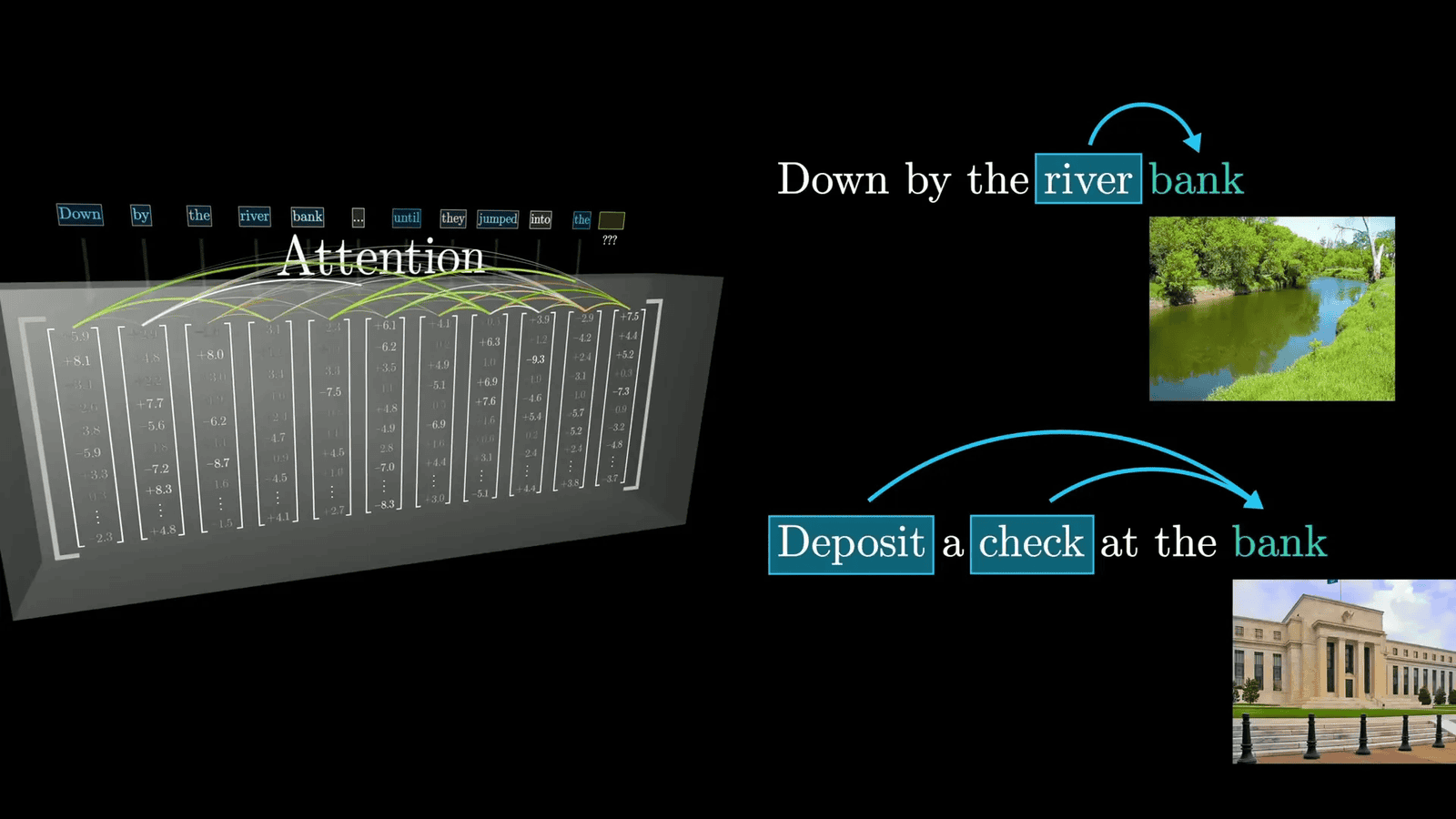
The attention mechanism is a defining feature of transformers. It allows the model to weigh the importance of different words in a sentence based on their context. This means that the model can focus more on certain words while generating predictions, which enhances its ability to produce relevant and coherent responses.
For example, in the phrase “bank of the river,” the model can adjust the meaning of the word “bank” based on its surrounding context, recognizing that it refers to a riverbank rather than a financial institution. This capability is what enables LLMs to generate more nuanced and contextually appropriate text.
Emergent Behavior in LLMs
Emergent behavior in Large Language Models (LLMs) refers to the unexpected capabilities that arise when these models are trained on large datasets. As LLMs learn from vast amounts of text, they often develop competencies that were not explicitly programmed into them. This includes generating creative content, engaging in complex dialogue, and even solving problems.
Such behaviors stem from the intricate interplay of the model’s parameters, which can lead to surprising outcomes. For instance, an LLM might learn to mimic different writing styles or respond to queries in a manner that showcases a nuanced understanding of context. This phenomenon highlights the sophistication of LLMs and challenges our traditional notions of machine learning.
Examples of Emergent Behavior
- Creative Writing: LLMs can generate poetry, stories, and other forms of creative writing that often surprise users with their depth and originality.
- Language Translation: The ability of LLMs to translate languages has improved significantly, showcasing an understanding of context and idiomatic expressions.
- Problem Solving: Users often find that LLMs can tackle complex questions or problems, providing insightful answers that reflect a deeper comprehension of the subject matter.
The Practical Applications of LLMs
LLMs have a wide array of practical applications across various fields, transforming industries and enhancing productivity. Their ability to process and generate human-like text makes them invaluable tools for numerous tasks.
Applications in Different Fields
- Healthcare: LLMs assist in diagnosing conditions by analyzing patient data and providing potential treatment options based on existing medical literature.
- Education: In educational settings, LLMs can provide personalized tutoring, generate quizzes, and help students with writing assignments.
- Customer Support: Many businesses deploy LLMs in chatbots to handle customer inquiries efficiently, providing quick and accurate responses.
- Content Creation: Writers and marketers use LLMs to brainstorm ideas, draft articles, and optimize content for SEO, significantly speeding up the content creation process.
Benefits of Using LLMs
- Efficiency: LLMs can process large volumes of information quickly, making them ideal for tasks that require rapid data analysis.
- Scalability: They can be scaled to handle numerous tasks simultaneously, providing consistent performance across different applications.
- Cost-Effectiveness: Automating tasks with LLMs can reduce operational costs for businesses, allowing human workers to focus on more complex tasks.
Where to Learn More
For those interested in diving deeper into the world of Large Language Models (LLMs), there are numerous resources available that cater to various levels of expertise. Whether you’re a beginner or an experienced practitioner, you can find valuable information to enhance your understanding.
Recommended Resources
- Books: Look for titles focused on artificial intelligence, machine learning, and natural language processing. Notable mentions include “Deep Learning” by Ian Goodfellow and “Speech and Language Processing” by Daniel Jurafsky and James H. Martin.
- Online Courses: Platforms like Coursera, edX, and Udacity offer courses on machine learning and deep learning, often featuring modules specifically on LLMs.
- Research Papers: Websites like arXiv.org host a plethora of research papers that explore the latest advancements in LLM technology. Reading these can provide insights into cutting-edge developments.
- YouTube Channels: Channels dedicated to AI and machine learning, such as those by Yannic Kilcher and 3Blue1Brown, provide engaging and informative videos on LLMs and their implications.

FAQ
What are Large Language Models (LLMs)?
LLMs are advanced AI systems that use deep learning techniques to process and generate human-like text. They are trained on vast datasets and can understand and produce language with remarkable fluency.
How do LLMs learn?
LLMs learn through a two-step process: pre-training, where they analyze large amounts of text to predict the next word in a sequence, and fine-tuning, where they are adjusted based on specific tasks and human feedback.
What are some limitations of LLMs?
While LLMs are powerful, they can produce biased or inaccurate information based on the data they were trained on. Additionally, they lack true understanding and reasoning capabilities, often generating plausible but incorrect responses.
Can LLMs replace human jobs?
LLMs can automate certain tasks, increasing efficiency and productivity. However, they are best viewed as tools that augment human capabilities rather than outright replacements for human jobs, especially in fields requiring creativity and critical thinking.



